Abstract
Humans are efficient language learners and inherently social creatures. Our language development is largely shaped by our social interactions, for example, the demonstration and feedback from caregivers. Contrary to human language learning, recent advancements in large language models have primarily adopted a non-interactive training paradigm, and refined pre-trained models through feedback afterward.
In this work, we explore how corrective feedback from interactions influences neural language acquisition from scratch through systematically controlled experiments, assessing whether it contributes to word learning efficiency in language models. We introduce a trial-and-demonstration (TnD) learning framework that incorporates three distinct components: student trials, teacher demonstrations, and a reward conditioned on language competence at various developmental stages.
Our experiments reveal that the TnD approach accelerates word acquisition for student models of equal and smaller numbers of parameters, and we highlight the significance of both trials and demonstrations. We further show that the teacher's choices of words influence students' word-specific learning efficiency, and a practice-makes-perfect effect is evident by a strong correlation between the frequency of words in trials and their respective learning curves. Our findings suggest that interactive language learning, with teacher demonstrations and active trials, can facilitate efficient word learning in language models.
Introduction
Humans are social beings and we learn language from interactions. Long before children's linguistic skills are mature, they could engage in early forms of conversational exchange with others. A critical component of social interactions that language grounds to is the feedback provided by the caregivers. This includes the communicative feedback that highlights the success and failure of communication, and the corrective feedback that is more direct and emphasizes the responses from caregivers, which offer corrections to possible errors in children's speech.
Unlike human learners who acquire language skills through feedback during interactions, most language models differ in terms of their inductive biases and data sources. These models typically learn from massive text corpora using cross-entropy loss for self-supervised learning.
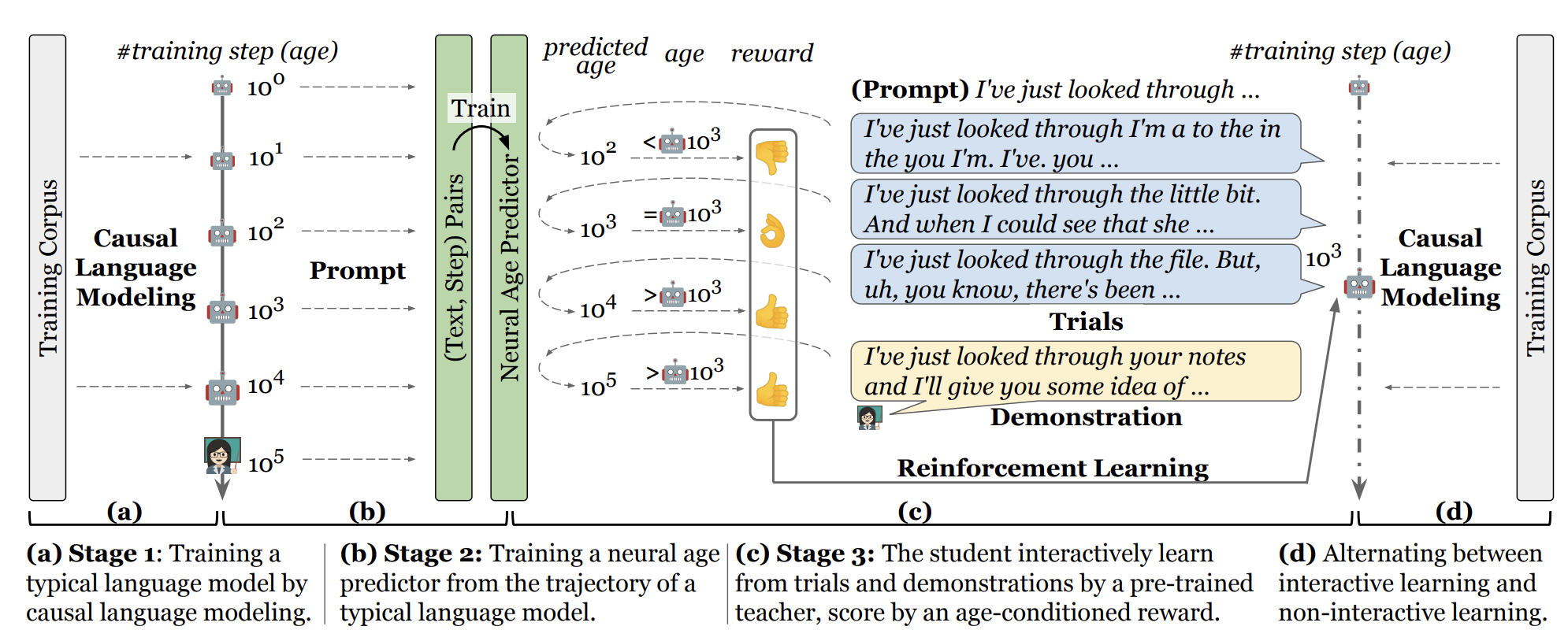
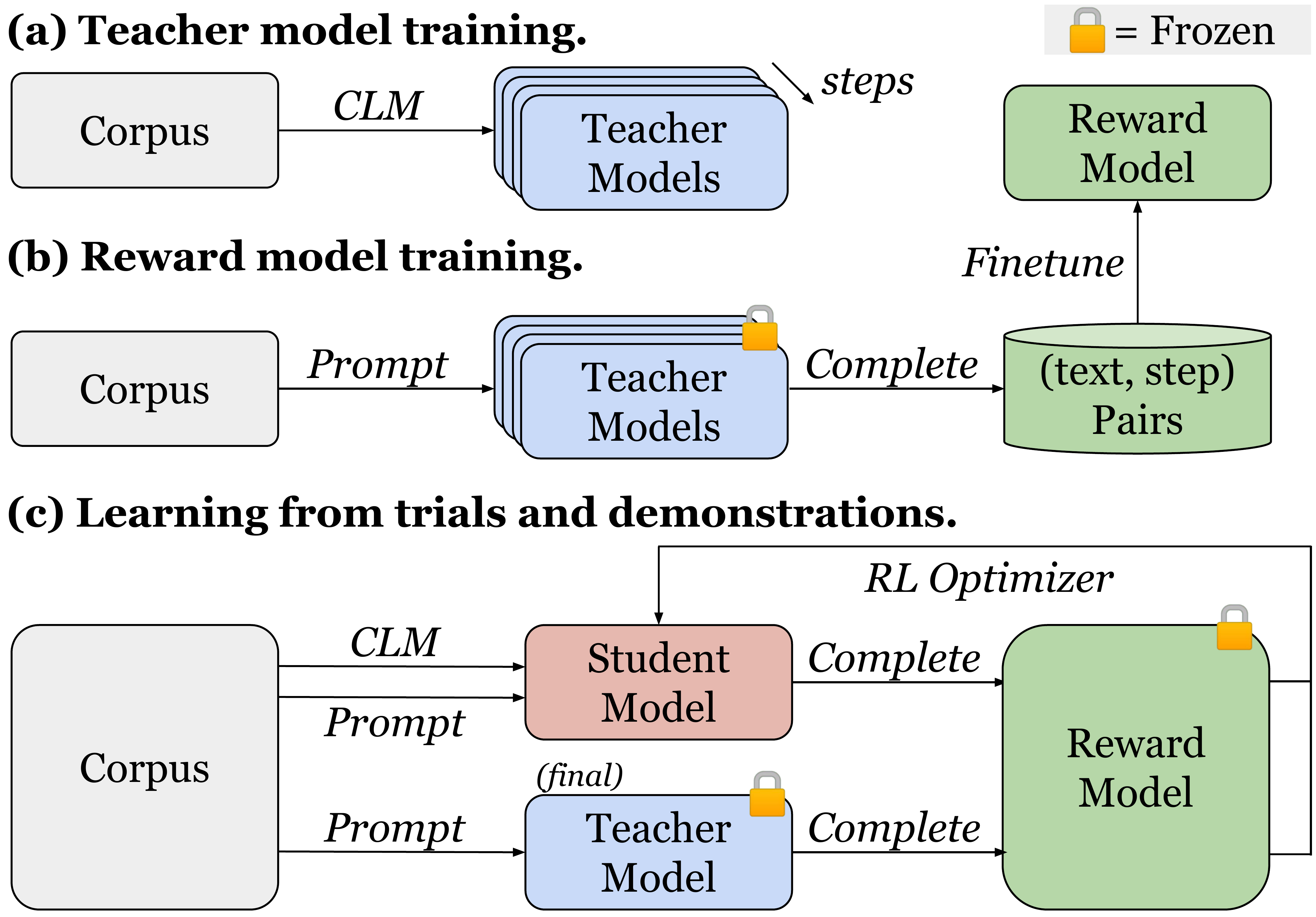 The Trial-and-Demonstration (TnD) learning framework incorporates three components: (a) A teacher model pre-trained with causal language modeling (CLM), (b) A student model that learns via alternating between CLM and reinforcement learning (RL), and (c) A reward conditioned on the neural age of the student model.
The Trial-and-Demonstration (TnD) learning framework incorporates three components: (a) A teacher model pre-trained with causal language modeling (CLM), (b) A student model that learns via alternating between CLM and reinforcement learning (RL), and (c) A reward conditioned on the neural age of the student model.
Trial-and-Demonstration (TnD) Learning Framework
We introduce Trial-and-Demonstration (TnD), an interactive learning framework that incorporates corrective feedback with three components: student model trials, teacher model demonstrations, and a reward conditioned on the training trajectory of the model.
In this framework, the student model engages in production-based learning: to produce an initial utterance, followed by the teacher model generating its version of the text as a demonstration. For the student model to recognize the teacher's response as preferable and to facilitate learning, these language outputs are evaluated by a reward function, which is based on the competence of the student's language use that is expected for its developmental stage (i.e., training steps).
Components of the TnD Framework
The Student Model and Trials
We employ randomly initialized GPT-2 as the student model for our investigation into language acquisition, leveraging its causal language modeling (CLM) objective and inherent generative capabilities for production-based learning. To encourage the student model to attempt text production, it is essential to provide an appropriate context. In each trial, we prompt the student with the first 5 tokens from a natural sentence, asking it to generate the continuation as a trial.
The Teacher Model and Demonstrations
We utilize pre-trained language models as proxies for human language teachers. Employing language models as "caregivers" for language models offers two advantages: it eliminates the need for recruiting human participants across thousands of iterations, and we can consistently control the behavior of the teacher model across experiments.
The process of developing a teacher model is identical to the typical language model pre-training. We adopted the same GPT-2 architecture and pre-trained the model with the CLM objective. To generate a natural language demonstration for the student's trial, we prompt the pre-trained teacher model with the same 5 tokens used for the student model, thereby obtaining the teacher's completion of the sentence.
The Reward and Reward Model
Defining an effective reward in our context is challenging due to the absence of communication games and the lack of access to large-scale human preference annotations. Heuristic reward metrics do not consider the developmental trajectory of language models, which is critical for simulating language acquisition.
We treat the number of training steps as the neural model's "age". A language model that generates fluent text at 500 steps, which typically emerges around 5,000 steps, should be rewarded for its accelerated learning. Conversely, if the language production quality in the student remains the same at 50,000 steps, it should be penalized.
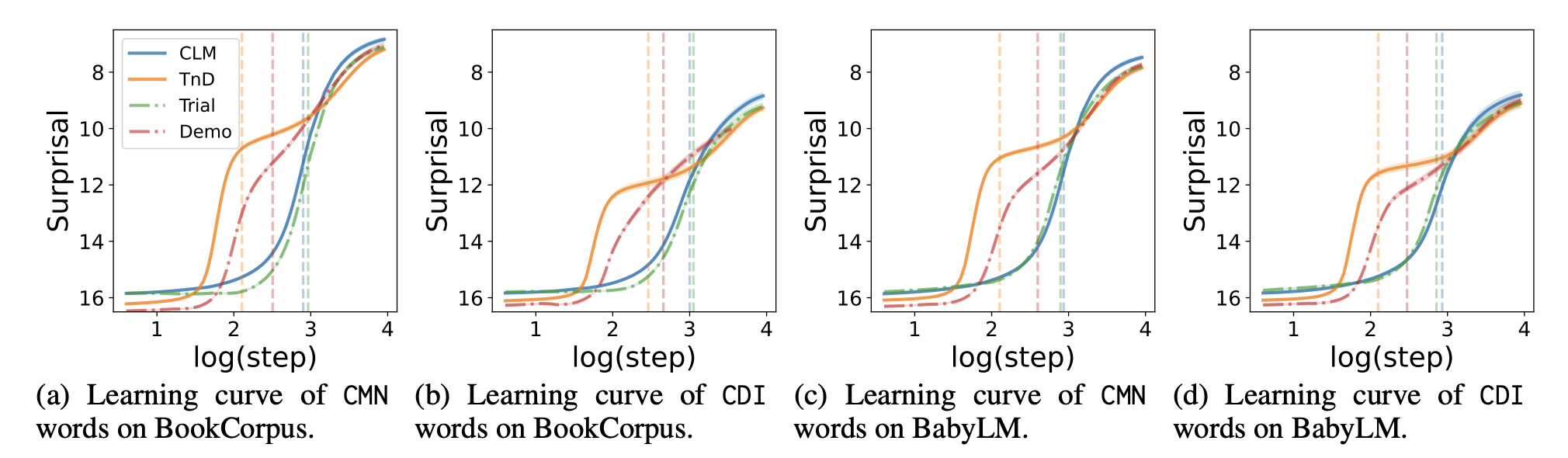
 Learning curves of word acquisition for different models. The TnD approach accelerates word learning compared to other baselines, highlighting the importance of both trials and demonstrations in the learning process.
Learning curves of word acquisition for different models. The TnD approach accelerates word learning compared to other baselines, highlighting the importance of both trials and demonstrations in the learning process.
Key Findings
Corrective Feedback Accelerates Neural Word Acquisition
Our experiments reveal that the TnD learning framework significantly accelerates word acquisition in training, outperforming other baselines. This acceleration is attributed to the critical roles of both trials and demonstrations in the learning process. With only teacher demonstrations, the student model acquires words faster than with the plain CLM baseline alone, though not as rapidly as when active trials are incorporated in the TnD framework.
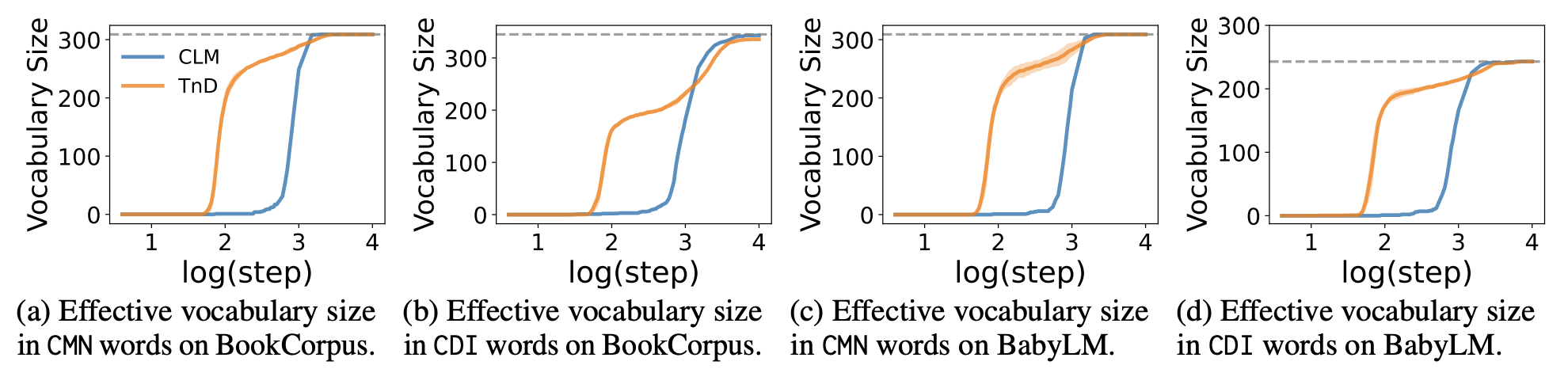
 Growth of effective vocabulary size over training steps. The TnD model picks up a larger effective vocabulary much faster than other approaches.
Growth of effective vocabulary size over training steps. The TnD model picks up a larger effective vocabulary much faster than other approaches.
Corrective Feedback Helps Knowledge Distillation for Smaller Student Models
We investigated whether our approach could distill linguistic knowledge to smaller student models. We found that such efficient language learning can still be observed, even when the setting is translated to smaller models. Each TnD model outperforms the CLM baseline of the same size and even surpasses CLM baselines of large capacity in early steps.
 TnD accelerates word acquisition for smaller student models. Each smaller TnD model outperforms its CLM counterpart of the same size.
TnD accelerates word acquisition for smaller student models. Each smaller TnD model outperforms its CLM counterpart of the same size.
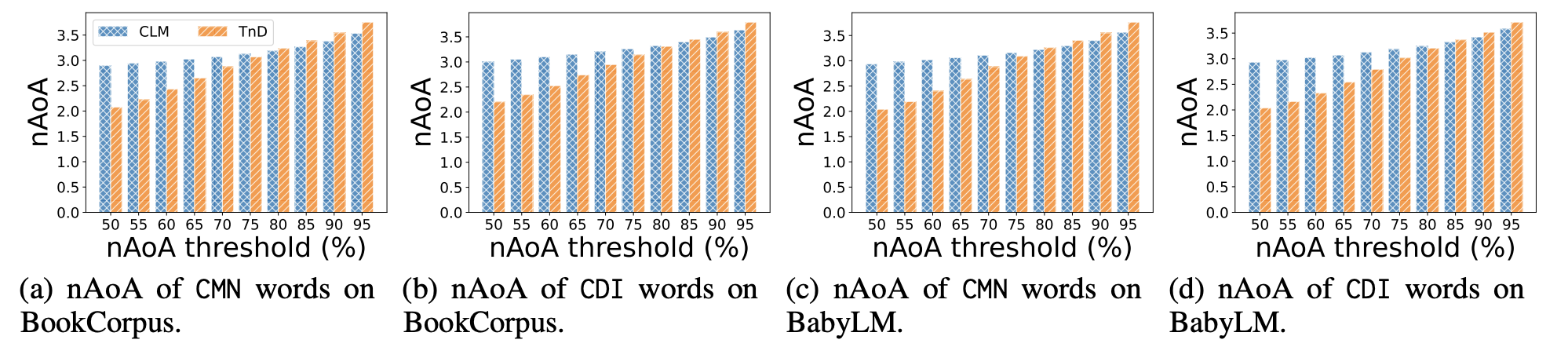
Teacher's Word Preferences in Demonstrations Affect Students
Our findings indicate that the teacher model's word choices significantly influence the efficiency of word acquisition by the student model. The absence of words from teacher demonstrations leads to slower learning speed for student models, as evidenced by a higher neural age of acquisition (nAoA), although the student models are ultimately able to learn these words from the corpus and their trials.
Practice Makes Perfect in Trials
We observe that the learning curves for certain words exhibit a pronounced correlation with the frequency of these words in trials. Our analysis reveals that the cumulative frequency of words encountered in trials plays a significant role in the acquisition of functional words and predicates. However, this significant contribution does not extend to nouns, indicating a potential impact of active trials on different parts of speech within the learning process.
 The relationship between word frequency in trials and learning curves for selected words. There's a strong correlation between how often certain words appear in trials and how quickly they are learned.
The relationship between word frequency in trials and learning curves for selected words. There's a strong correlation between how often certain words appear in trials and how quickly they are learned.
Conclusion
This research introduces a trial-and-demonstration (TnD) learning framework to examine the effectiveness of corrective feedback in neural word acquisition through systematically controlled experiments, assessing how the interplay between student trials and teacher demonstrations contributes to learning efficiency in neural language models.
We find that (1) TnD learning accelerates neural word acquisition across student models of different sizes; (2) the teacher's choices of words influence students' word-specific learning efficiency; and (3) a practice-makes-perfect effect is evident by a strong correlation between the frequency of words in trials and their respective learning curves. Our findings confirm the crucial role of interaction in efficient word learning with language models.