Abstract
The ability to connect language units to their referents in the physical world, referred to as grounding, is crucial to learning and understanding grounded meanings of words.
While humans demonstrate fast mapping in new word learning, it remains unclear whether modern vision-language models can truly represent language with their grounded meanings, and how grounding may further bootstrap new word learning.
To this end, we introduce Grounded Open Vocabulary Acquisition (GOVA) to examine grounding and bootstrapping in open-world language learning.
As an initial attempt, we propose object-oriented BERT (OctoBERT), a novel visually-grounded language model by pre-training on image-text pairs highlighting grounding as an objective.
Through extensive experiments and analysis, we demonstrate that OctoBERT is a more coherent and fast grounded word learner, and that the grounding ability acquired during pre-training helps the model to learn unseen words more rapidly and robustly.
Introduction
Language is learned through sensorimotor experience in the physical world.
The ability to connect language units to their referents in the physical world, i.e. (referential) grounding, plays an important role in learning and understanding grounded meanings of words.
As shown in Figure 1, a human reader would easily ground noun phrases to the corresponding entities captured in the image.
Even when the term "incinerator" is new to human learners, they can still locate the object of interest through the language and visual context, and acquire its meaning.
In fact, this ability to bootstrap new word learning with only minimal information, known as fast mapping, is demonstrated abundantly in cognitive literature on human language acquisition.
 Even when the term "
Even when the term "incinerator" (highlighted yellow) is new to human learners, they can still locate the most likely referent (indicated by the yellow bounding box) in the perceived world by grounding.
Recently, there has been a substantial effort on pre-training vision-language models (VLMs).
Despite the exciting performance of these models on a variety of downstream vision and language tasks, it remains unclear whether these models can truly understand or produce language with their grounded meanings in the perceived world, and how grounding may further bootstrap new word learning.
These questions are of interest from both a scientific and an engineering point of view.
Grounded Open Vocabulary Acquisition (GOVA)
We introduce Grounded Open Vocabulary Acquisition (GOVA), a scalable formulation to examine grounding and bootstrapping in open-world language learning.
In this formulation, language learning is a combination of learning to predict a word in a linguistic context as well as learning to ground the word in the physical world.
 An instance of the word grounding task. Models are tasked to predict the missing word "
An instance of the word grounding task. Models are tasked to predict the missing word "boat" and localize the corresponding smaller yellow boat in the image coherently.
Under this formulation, we explore the framework in which the model first acquires the grounding ability during pre-training, and then transfers this ability to learn unseen words without grounding supervision.
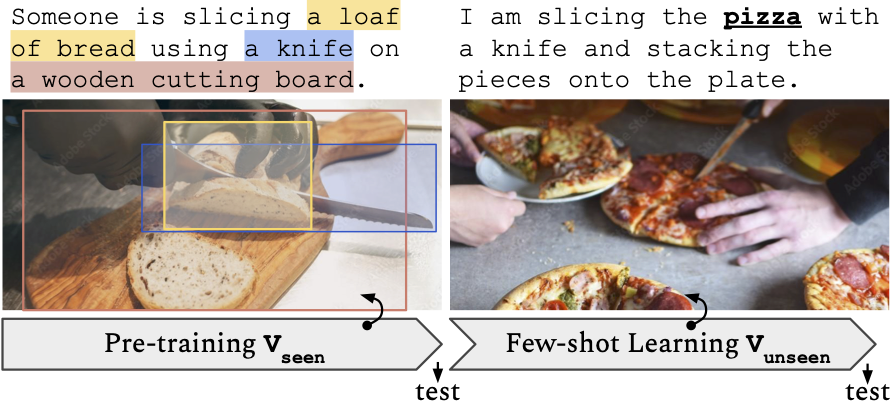 An illustration of the few-shot new word learning paradigm. The model first pre-trains on a grounding dataset with a set of base words (V_seen), and then attempts to acquire a set of unseen words (V_unseen) in a small number of raw text-image pairs.
An illustration of the few-shot new word learning paradigm. The model first pre-trains on a grounding dataset with a set of base words (V_seen), and then attempts to acquire a set of unseen words (V_unseen) in a small number of raw text-image pairs.
Object-Oriented BERT (OctoBERT)
As an initial step, we developed object-oriented BERT (OctoBERT), a novel visually grounded language model motivated by recent advances in detection transformers (DETR).
Compared to many existing VLMs, OctoBERT performs language modeling upon explicit object representations.
The model first acquires the ability to ground during pre-training, and then transfers this intrinsic ability to learn unseen words when grounded supervision is no longer available.
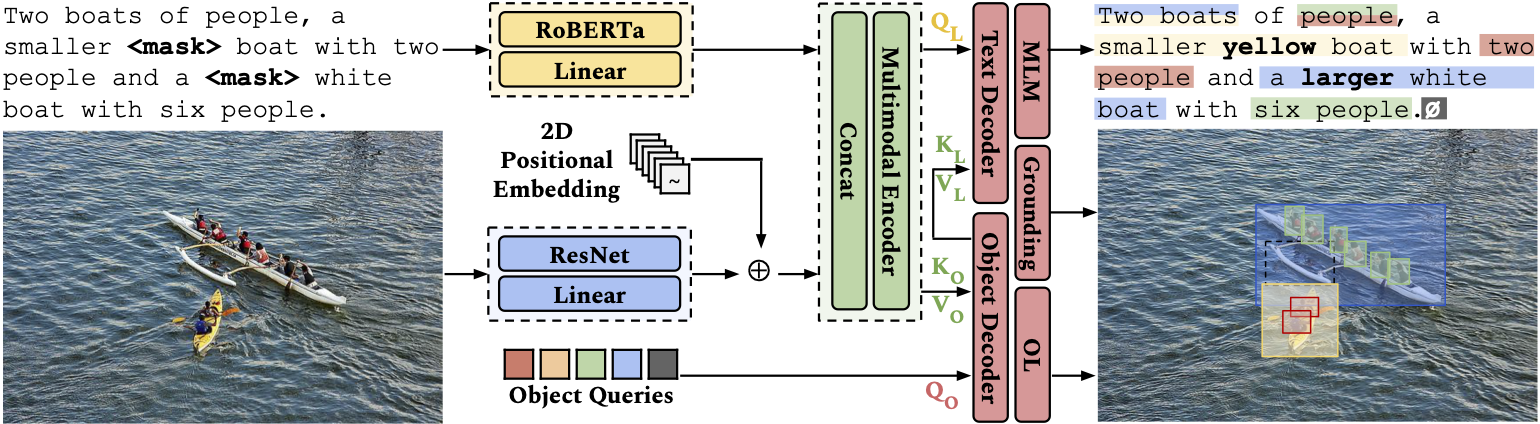 An overview of
An overview of OctoBERT, a visually grounded language model pre-trained with three objectives: masked language modeling (MLM), object localization (OL), and grounding through word-region alignment (WRA).
Key Findings
Our empirical results show that learning to map words to their referents plays a significant role in grounded word acquisition. By pre-training with fine-grained word-object mappings, OctoBERT demonstrates stronger performance in learning grounded meanings of words, both seen and unseen, yet with orders of magnitude fewer data compared to other competitive VLM baselines.
The pre-trained model can further provide a foundation for efficient learning of new grounded words with a few examples. We further present an in-depth analysis to understand potential predictors of VLMs in word learning, which demonstrates intriguing behaviors in comparison to human language learning.
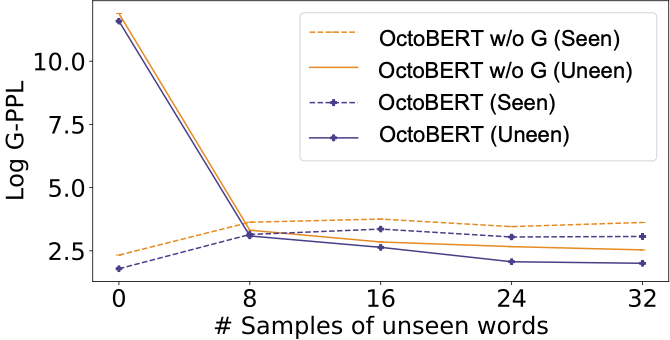 The log G-PPL (All-Protocol) of seen and unseen words in multi-class incremental learning, each unseen word with a sample size ranging from 8 to 32.
The log G-PPL (All-Protocol) of seen and unseen words in multi-class incremental learning, each unseen word with a sample size ranging from 8 to 32.
Conclusion
The connection between language and their referents captures the grounded meaning of words, and an explicit treatment is key to empowering efficient open-world language learning abilities in humans and AI agents. This work introduces Grounded Open Vocabulary Acquisition (GOVA), a scalable formulation to examine grounding and fast mapping in open-world grounded language learning. Our findings pave the way for future research in grounded language learning in the open world.