Abstract
Improvements in language model capabilities are often attributed to increasing model size or training data, but in some cases smaller models trained on curated data or with different architectural decisions can outperform larger ones trained on more tokens. What accounts for this?
To quantify the impact of these design choices, we meta-analyze 92 open-source pretrained models across a wide array of scales, including state-of-the-art open-weights models as well as less performant models and those with less conventional design decisions. We find that by incorporating features besides model size and number of training tokens, we can achieve a relative 3-28% increase in ability to predict downstream performance compared with using scale alone.
Analysis of model design decisions reveal insights into data composition, such as the trade-off between language and code tasks at 15-25% code, as well as the better performance of some architectural decisions such as choosing rotary over learned embeddings.
Broadly, our framework lays a foundation for more systematic investigation of how model development choices shape final capabilities.
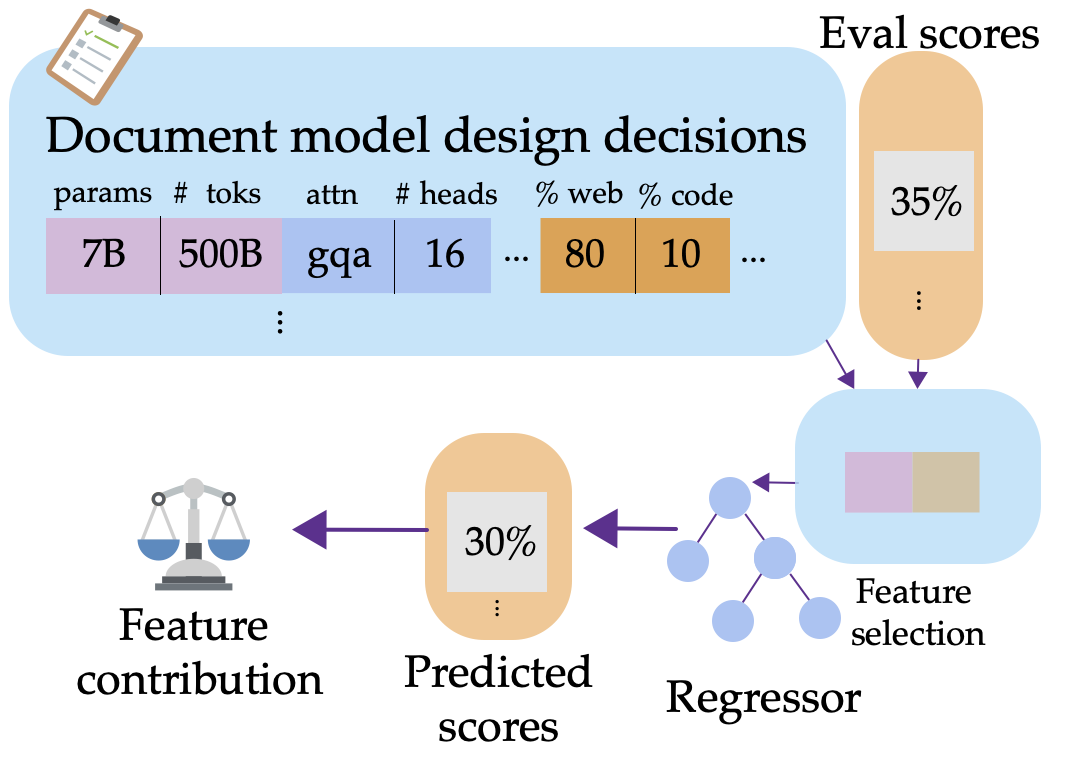 We document design decisions from open-weights models related to both architecture and data composition, and train predictors for downstream task performance. This allows us to examine the impact of model design choices individually.
We document design decisions from open-weights models related to both architecture and data composition, and train predictors for downstream task performance. This allows us to examine the impact of model design choices individually.
Introduction
The effectiveness of language model training depends critically on decisions made during pretraining. Language model performance has been found to be fairly predictable through scaling laws — extrapolations of model performance based on the parameter counts and number of tokens the models were trained on. However, scaling laws based on only these two aspects do not always explain downstream task performance.
We ask: can we leverage past findings from open language models to examine how training decisions jointly impact downstream performance?
Building a Database of Publicly-Available Language Models
To approach our research question, we built a comprehensive database of publicly available language models. Our database encompasses models spanning a wide range of sizes, from 11M to 110B parameters, and includes only distinct pretrained base models with decoder-only architectures. We applied the following criteria:
- Pretrained-only: Only base models that were pretrained from scratch were included. Fine-tuned variants, merged models, and models with additional post-training were excluded.
- Architecture: Only transformer-based decoder-only models were included to maintain uniformity. Mixture-of-experts (MoEs) or other architectures were excluded.
- Publicly available information: Only models with publicly available metadata, documented through configuration files or papers, were included.
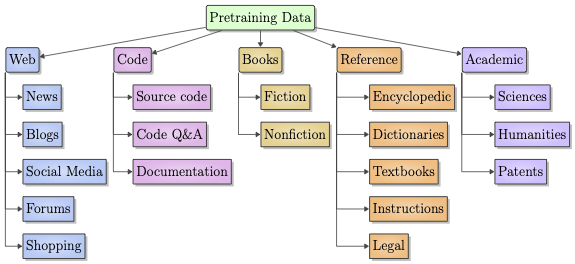 Taxonomy of pretraining data categories. We sorted data sources into this taxonomy based on model documentation.
Taxonomy of pretraining data categories. We sorted data sources into this taxonomy based on model documentation.
Different Tasks, Different Scaling Trends
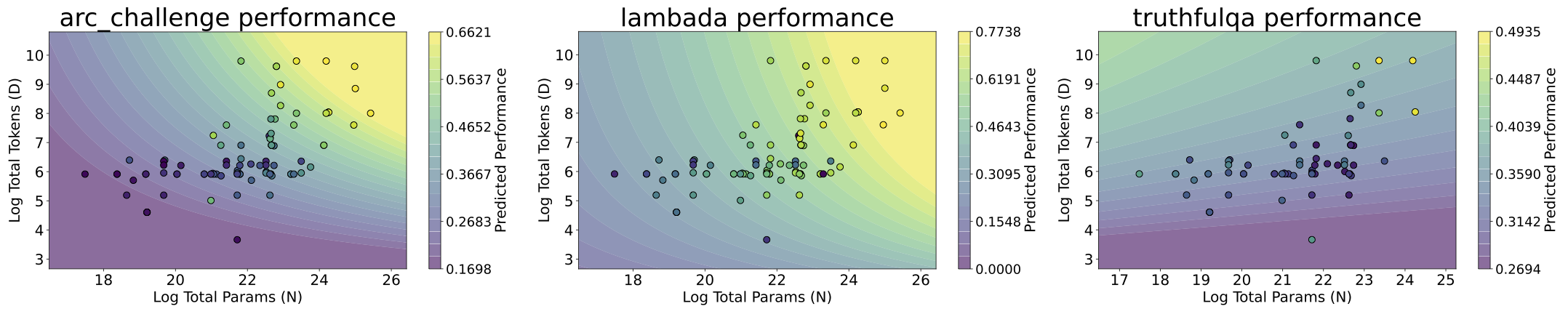 Performance plotted against their total parameters and tokens. The background color represents the scaling law fitted to the task, and the marker colors indicate true performance. Some tasks have different performance trends with scale.
Performance plotted against their total parameters and tokens. The background color represents the scaling law fitted to the task, and the marker colors indicate true performance. Some tasks have different performance trends with scale.
Before adding in other factors, we examine differences in scaling along parameters and tokens between our selected tasks. We find that different tasks may exhibit marked differences both in how well they follow scaling trends, as well as their individual scaling contours. For instance, TruthfulQA appears to exhibit U-shaped scaling, while Humaneval has more "outlier" models.
Key Findings
It's Not Just Scaling
We find that incorporating extra features alongside traditional scaling laws features leads to substantial improvements in prediction accuracy across multiple benchmarks. The all-features predictor outperforms the scaling-laws-only predictor in all evaluated cases, with improvements ranging from approximately 3% (MathQA) to about 28% (Lambada) relative error reduction.
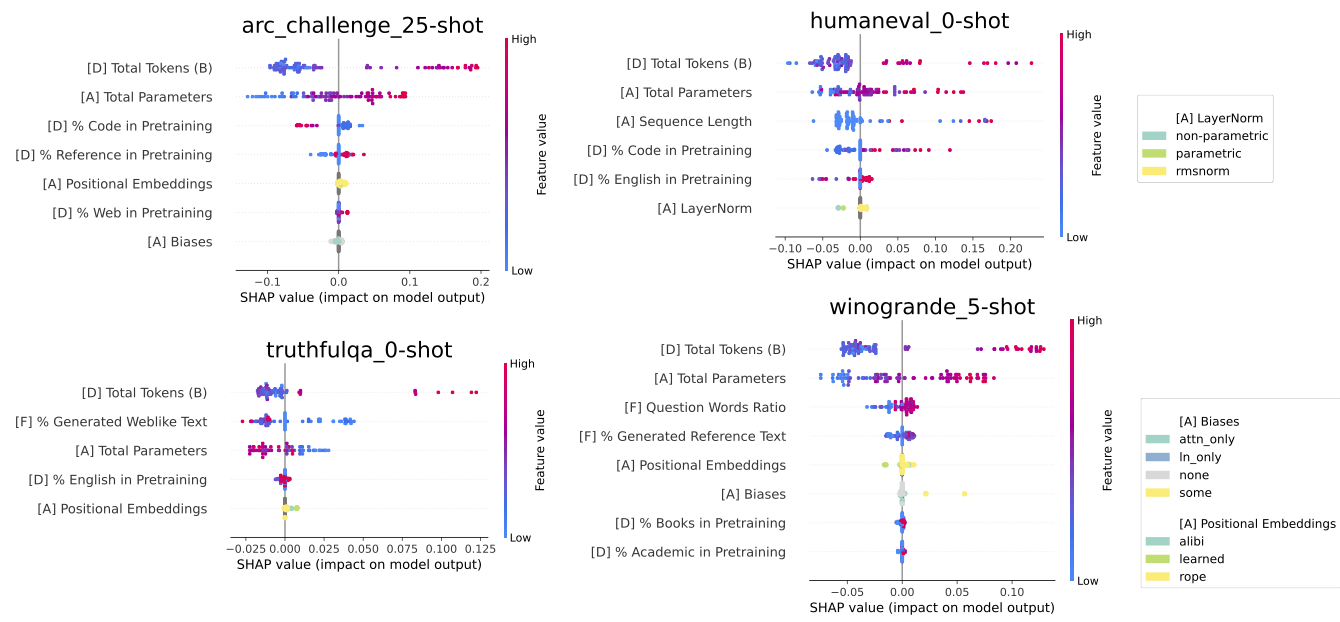 In all tasks, the number of parameters and pretraining tokens heavily influences the predictions made by the regressor. The percentage of code in pretraining often influences predictions negatively for NLI tasks but positively for Humaneval.
In all tasks, the number of parameters and pretraining tokens heavily influences the predictions made by the regressor. The percentage of code in pretraining often influences predictions negatively for NLI tasks but positively for Humaneval.
A Little Code Goes a Long Way, but Too Much is Harmful to NLI
One of the most important non-scaling features is the percentage of code data in pretraining. Higher code composition results in positive Shapley values (i.e. higher predicted performance) for Humaneval, but it negatively affects Arc Challenge, Hellaswag, Winogrande, and Lambada.
Models trained with more than roughly 20–25% code are predicted to have large gains on tasks like Humaneval, but start to incur penalties on standard natural language benchmarks. By contrast, a moderate code proportion in the 15–25% range appears to balance these competing demands, yielding a more neutral or slightly positive effect overall.
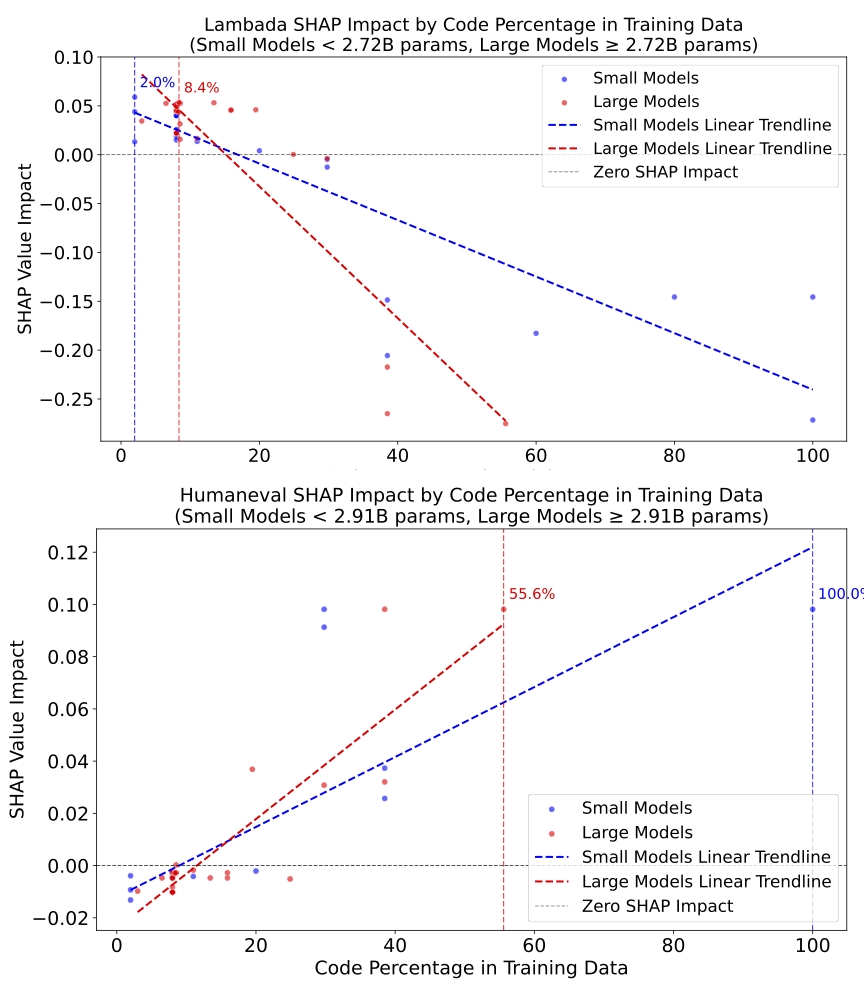 SHAP impact of code percentage on Lambada (representative NL task) and Humaneval on our regressors.
SHAP impact of code percentage on Lambada (representative NL task) and Humaneval on our regressors.
Other Insights on Task Performance
From the fine-grained features from free generations, we also observed that many recent models (particularly those trained on synthetic data such as the Phi and SmolLM) generate a relatively large number of question words, indicating extensive training on data related to question answering.
A higher percentage of reference-like or question-loaded generations resulted in better model accuracy on some tasks such as Arc Challenge and Winogrande. Additionally, models that generate more web-like data tend to do worse on TruthfulQA.
Conclusion
We perform the first systematic analysis of the performance of open language models across diverse tasks and tie their performance to architectural and data-compositional design decisions.
Our database can be further expanded as new models and benchmarks are released, and we will release the code and data to help spur community efforts for more systematic data documentation.
We hope our work will help discover hypotheses to be tested in more controlled settings — existing models intertwine a number of design decisions, and further controlled pre-training experiments that only involve one axis of variation could further clarify the effect of each feature.