Abstract
While Multi-modal Large Language Models (MLLMs) demonstrate impressive abilities over high-level perception and reasoning, their robustness in the wild still lags behind humans and exhibits diminished efficacy on simple tasks that are intuitive for humans. We examine the hypothesis that these deficiencies stem from the absence of core knowledge—rudimentary cognitive abilities innate to humans from early childhood.
To probe core knowledge representation in MLLMs, we draw from developmental cognitive sciences and develop a large-scale benchmark, the CoreCognition dataset, encompassing 12 core cognitive concepts. We evaluate 219 models with 10 different prompts, leading to a total of 2409 data points for analysis. Our findings reveal core knowledge deficits in early-developed core abilities while models demonstrate human-comparable performance in high-level cognition. Moreover, we find that low-level abilities show little to no scaling, in stark contrast to high-level abilities. Finally, we introduce an evaluation technique "Concept Hacking," through which we demonstrate that MLLMs do not genuinely advance toward core knowledge but instead rely on illusory understanding and shortcut learning as they scale.
 Left: Data statistics of CoreCognition dataset. Right: Map of core cognitive abilities organized by developmental stage, with dependency relationships indicated by arrows.
Left: Data statistics of CoreCognition dataset. Right: Map of core cognitive abilities organized by developmental stage, with dependency relationships indicated by arrows.
Core Cognitive Abilities
Our study examines 12 core cognitive abilities organized across three developmental stages based on Piaget's theory of cognitive development:
Sensorimotor Stage
- Boundary: The transition from existence to non-existence of objects
- Continuity: Physical properties of objects tend to exist in the same way
- Permanence: Things continue to exist when they are not in sight
- Spatiality: The a priori understanding of the Euclidean properties of our world
- Perceptual Constancy: Changes in appearances don't mean changes in physical properties
Concrete Operational Stage
- Intuitive Physics: Intuitions about the laws of how things interact in the physical world
- Perspective Taking: To see what others see
- Hierarchy: Understanding of inclusion and exclusion of objects and categories
- Conservation: Invariances of properties despite transformations
Formal Operational Stage
- Tool Use: The capacity to manipulate specific objects to achieve goals
- Intentionality: To see what others want
- Mechanical Reasoning: Inferring actions from system states and vice versa
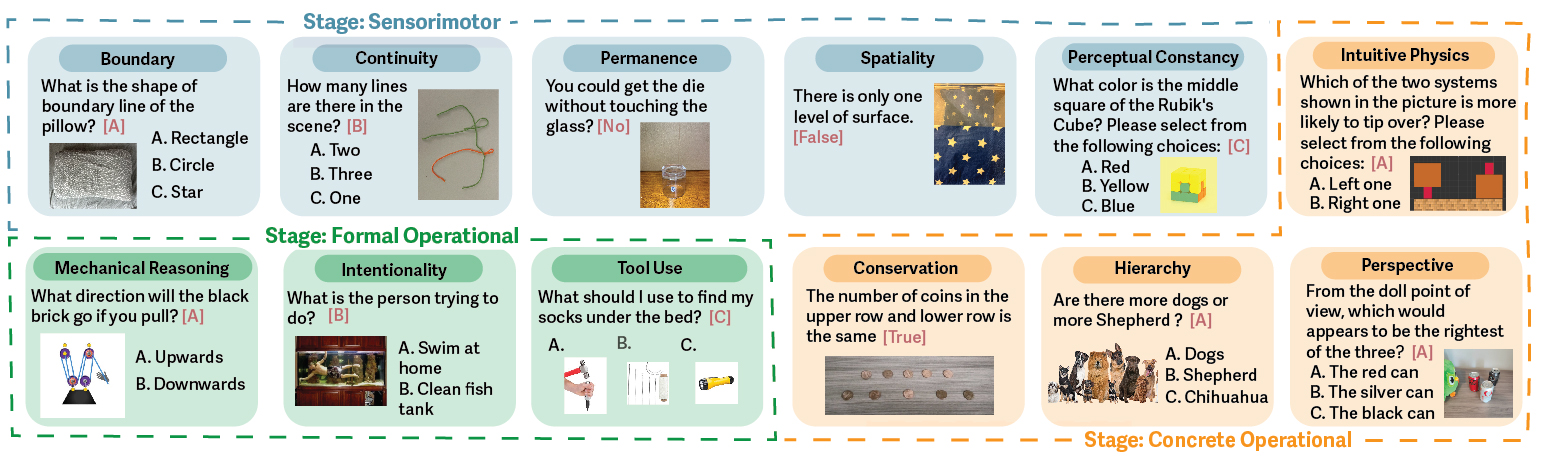 Examples of tasks from the CoreCognition dataset, illustrating how each cognitive ability is assessed.
Examples of tasks from the CoreCognition dataset, illustrating how each cognitive ability is assessed.
Key Findings
MLLMs Show Reversed Cognitive Development
We found that MLLMs perform significantly better on tasks associated with later stages of cognitive development (Formal Operational), while their performance was comparatively worse on tasks that typically emerge earlier in human cognition (Sensorimotor). This suggests a rather unusual "reversed cognitive developmental trajectory" in these models.
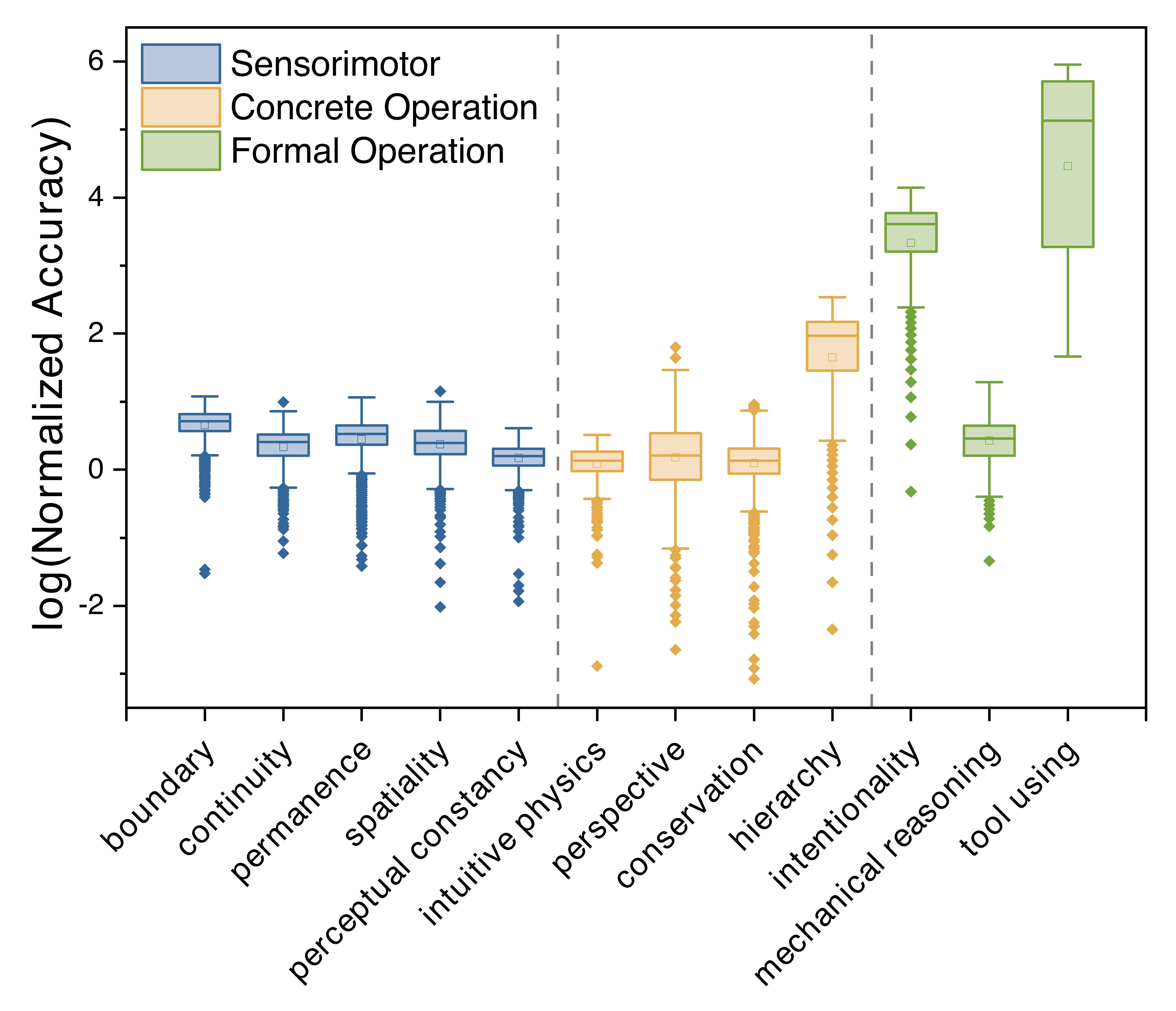 MLLMs demonstrate better performance on higher-level abilities (Formal Operational) than on lower-level abilities (Sensorimotor), which is contrary to human cognitive development.
MLLMs demonstrate better performance on higher-level abilities (Formal Operational) than on lower-level abilities (Sensorimotor), which is contrary to human cognitive development.
Core Knowledge Deficits Don't Improve with Scale
Our scaling analysis revealed that while high-level abilities improve with larger model sizes, low-level abilities show minimal or no improvement. Some abilities, like perspective-taking, even deteriorate with increased scale. This indicates that simply increasing model parameters won't address core knowledge deficits.
 Scaling laws do not apply uniformly across all cognitive abilities. While high-level abilities improve with model size, low-level abilities show little to no improvement.
Scaling laws do not apply uniformly across all cognitive abilities. While high-level abilities improve with model size, low-level abilities show little to no improvement.
Concept Hacking: Models Rely on Shortcuts, Not Core Knowledge
To probe whether models genuinely understand core concepts or merely exploit statistical correlations, we developed "Concept Hacking" - a method that manipulates task-relevant details to invert the ground truth while preserving irrelevant conditions. Our analysis revealed that models either rely on shortcuts from their training data or possess illusory understandings that are opposite to reality, rather than developing true core knowledge.
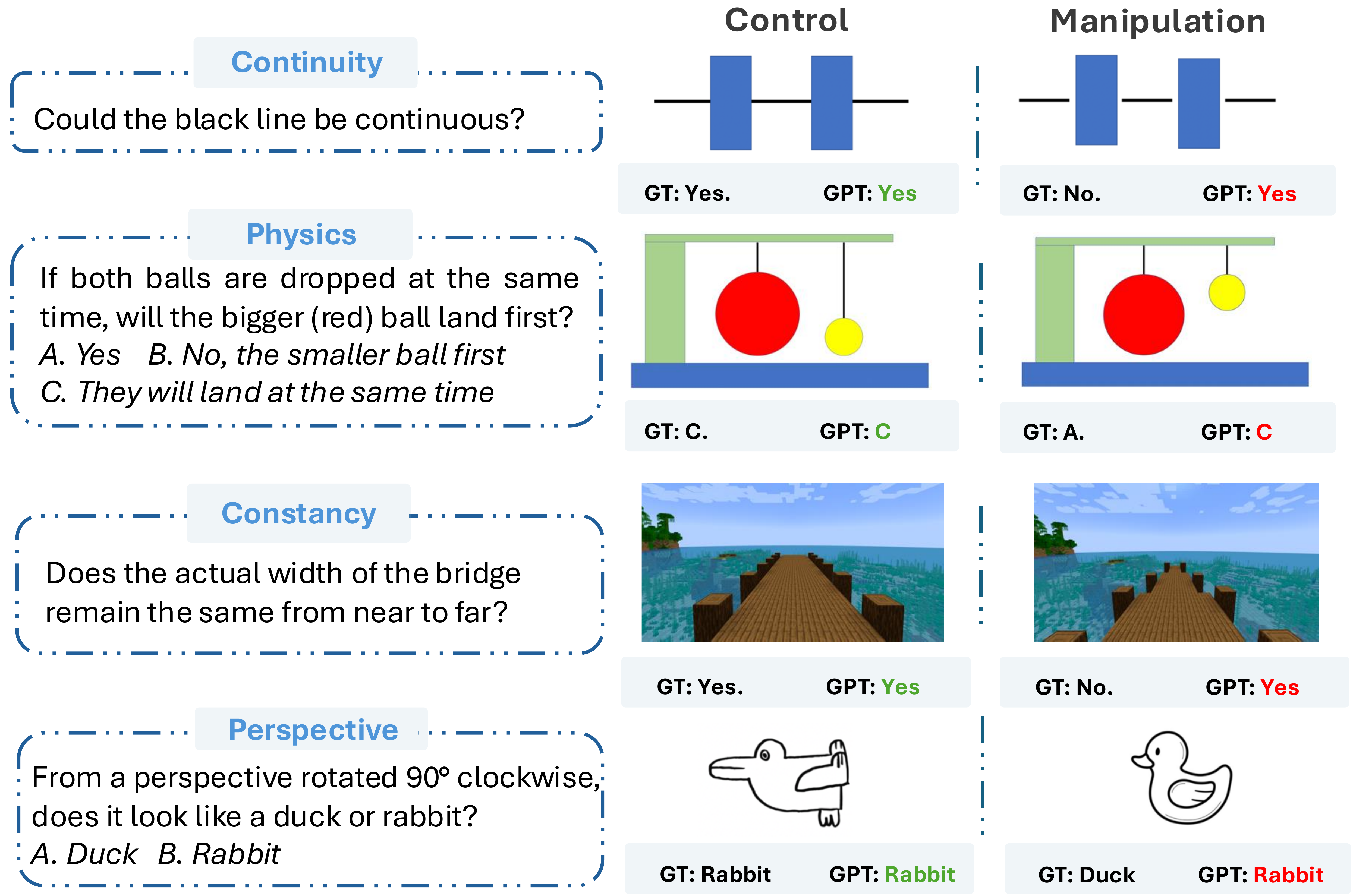 Examples of Concept Hacking methodology. Left: A model relying on shortcuts would succeed in the standard task but fail the manipulated one. Right: A model with an illusory understanding would fail the standard task but succeed in the manipulated version.
Examples of Concept Hacking methodology. Left: A model relying on shortcuts would succeed in the standard task but fail the manipulated one. Right: A model with an illusory understanding would fail the standard task but succeed in the manipulated version.
 Accuracy of MLLMs on Control vs. Manipulation tasks in Concept Hacking. As models scale, they increasingly rely on either shortcuts or illusory understandings rather than developing true core knowledge like humans (who would progress along the diagonal).
Accuracy of MLLMs on Control vs. Manipulation tasks in Concept Hacking. As models scale, they increasingly rely on either shortcuts or illusory understandings rather than developing true core knowledge like humans (who would progress along the diagonal).
Implications
Our findings suggest that current MLLMs exhibit fundamental core knowledge deficits—they lack a basic understanding of key domains such as objects, actions, numbers, space, and social relations, which humans possess from infancy. While these models can perform impressively on high-level tasks, they achieve this through shortcuts and statistical correlations rather than through a genuine understanding of how the world works.
This has important implications for the development of robust AI systems. Without core knowledge to ground their reasoning, MLLMs may continue to struggle with generalization and robustness in real-world scenarios. Our results suggest that addressing these deficits may require architectural innovations beyond simply scaling up current models.