Qingying Gao1,*, Yijiang Li2, Haiyun Lyu3, Haoran Sun1, Dezhi Luo4,*, Hokin Deng5,*
1Johns Hopkins University, 2University of California, San Diego, 3University of North Carolina at Chapel Hill, 4University of Michigan, 5Carnegie Mellon University
* qgao14@jh.edu, ihzedoul@umich.edu, hokind@andrew.cmu.edu
Abstract
Knowing others' intentions and taking others' perspectives are two core components of human intelligence that are considered to be instantiations of theory-of-mind. Infiltrating machines with these abilities is an important step towards building human-level artificial intelligence. Here, to investigate intentionality understanding and level-2 perspective-taking in Vision Language Models (VLMs), we constructed the IntentBench and PerspectBench, which together contains over 300 cognitive experiments grounded in real-world scenarios and classic cognitive tasks. We found VLMs achieving high performance on intentionality understanding but low performance on level-2 perspective-taking. This suggests a potential dissociation between simulation-based and theory-based theory-of-mind abilities in VLMs, highlighting the concern that they are not capable of using model-based reasoning to infer others' mental states.
Keywords: vision language models; perspective-taking; intentionality understanding; theory-of-mind; cognitive AI
Introduction
Intentionality is the capacity of the mind to be directed toward, represent, or stand for objects, properties, or states of affairs for further executable actions. To say one could understand intentionality is to say one has the capacity to comprehend the mental content for action in another mind. This capacity has been seen as a key distinction between humans and machines. It is argued that despite well manipulation of language symbols, machines cannot understand intentional meanings of others because it lacks theory-of-mind (ToM), the kind of abilities that allows one to infer the mental content of others. Nevertheless, several recent studies have showed that large language models (LLMs) and their supporting vision language models (VLMs) exhibit ToM abilities, thus calling for updated examinations of the nature of ToM and the potential for current and future artificial intelligence to possess such abilities.
We believe an important approach to said inquiry is examining the extent to which different ToM abilities necessitate model-based reasoning. Specifically, a distinction can be drawn between ToM abilities based on simulation-theory and theory-theory. The former involves the construction of an internal model of self-other relations to reason about the mental states of others, whereas the latter requires only the use of theoretical knowledge regarding the relations between mind and behavior. Whether current artificial intelligence systems possess internal models that are available for reasoning remains a key debate, with several influential accounts questioning the existence of model-based reasoning among LLMs. If this is indeed the case, then evidences regarding the possession of ToM abilities in VLMs above would imply that ToM abilities do not require mental simulation, and that mental simulation is not within the foundational capabilities of ToM systems.
We tested this critical prediction by assessing VLMs' ability to perform intentionality understanding and level-2 perspective-taking. ToM is commonly understood to be grounded in perspective-taking, a series of multi-level abilities that involves the cognitively undertaking of the perspective of another. Level-1 perspective-taking refers to the acknowledgement that different people can see different things, whereas level-2 perspective-taking involves the understanding of how another person may see the same thing differently. While level-1 perspective-taking emerges in humans as early as 2 years old, much older children are found to struggle with level-2 perspective-taking. This is likely because despite its relatively low level in the perspective-taking hierarchy, this ability requires model-based reasoning, exemplified in the visual domain as inferences based on mental rotation. On the other hand, while intentionality understanding involves high-level cognition and abstract reasoning, it is unclear whether this complex ability necessitate mental simulations. Assessing level-2 perspective-taking and intentionality understanding in VLMs could thus provide insights into not only VLMs' abilities within these two ToM domains but also how they mechanistically related in terms of information-processing. However, these areas remain largely unexplored in the current literature, and in intelligent systems beyond human beings.
To address this critical gap in the literature, we introduced IntentBench and PerspectBench, two targeted benchmarks designed to systematically evaluate the capabilities of current VLMs in intentionality understanding and level-2 perspective-taking, respectively.
Methods
Datasets
PerspectBench consists of 32 multi-image and 209 single-image format experiments based on classic cognitive tasks. IntentBench consists of 100 single-image format experiments based on real-world ambiguous social scenarios.
Cognitive Experiments
Level-2 Perspective-taking
In Piagetian developmental psychology, the acquisition of level-2 perspective-taking ability marks a milestone of human cognitive development for that it indicates the elimination of egocentrism -- the inability to consider perspectives other than one's own. The Three Mountain Task invented by Piaget is widely used in developmental psychology laboratories as the gold standard for testing level-1 and level-2 perspective-taking abilities in children. In a standard Three Mountain Task assessment, a child is instructed to position oneself in front of a model featuring three mountains. These mountains vary in size and are distinguished by unique characteristics: one is covered in snow, another has a red cross at its peak, and the third is topped with a hut. The child is then asked to perform a complete 360-degree examination of the model. Subsequently, another individual is introduced and takes a different vantage point to observe the model. The child is presented with several photographs that showcase various viewpoints of the model and is tasked with identifying which photograph accurately represents what the other person sees. At around four years of age, children typically select the photograph that matches their own perspective. By six years old, they begin to acknowledge viewpoints that differ from their own, and by the ages of seven to eight, they are generally able to reliably identify the perspective of another individual.
To test level-1 and level-2 perspective-taking in VLMs, we adapted the Three Mountain task into formats that are suitable for benchmarks with minimal confounding details while preserving real-life spatiality. In particular, we used groups of 3-4 commonly-seen elastic cans organized into different spatial patterns to mimic the mountain model. Like in the original task, we used a doll placed to face the organization from different angels as the object of perspective-taking.
 Figure 1: Example Experiments and Model Performances on PerspectBench
Figure 1: Example Experiments and Model Performances on PerspectBench
Intentionality Understanding
Intentionality understanding is believed to be grounded by rudimentary theory-of-mind abilities. In developmental psychology, a critical subset of intentionality understanding experiments involves tests of action understanding. Several computational hypotheses are proposed on how one could understand other people's actions: for example, action understanding could be computationally modeled as pure inference, as mental action simulation, or as inverse planning. Typically, cartoon stimuli built via physic simulation engine are used frequently in action understanding in developmental psychology. These stimuli are incorporated into IntentBench. However, a common critique of cognitive psychology tasks is that they lack realism and have limited applicability to real-world situations. Drawing inspiration from COIG-CQIA and its Ruozhiba dataset, many real-world ambiguous scenarios are incorporated into IntentBench for explicitly testing intentionality understanding in ethological conditions.
 Figure 2: Example Experiments and Model Performances on IntentBench
Figure 2: Example Experiments and Model Performances on IntentBench
Model Selection and Experiment
We evaluated three categories of VLMs. To ensure a fair comparison, all VLMs are evaluated on their ability to reason over images and texts under a zero-shot generation task. A complete list of models is reported in the results section as shown in Figure 3. Model size data are curated at the same time. The models are categorized as follows:
- Open-source VLMs with Multi-Image Reasoning: Includes models with different sizes and other variants such as CogVLM Series, Qwen series (Qwen-VL, Qwen-2), and Blip2, LLaVA-Next, which are capable of reasoning over interleaved multiple images and texts.
- Closed-source VLMs with Multi-Image Reasoning: Includes proprietary models such as GPT series (GPT-4v, GPT-4-turbo, GPT-4o-mini), Gemini Series, and Claude Series. These models also support reasoning across interleaved images and texts.
- Open-source VLMs with Single-Image Reasoning: Includes models designed to process a single image alongside continuous text. InstructBlip Series, LLaVA Series.
In total, we processed 37 models for evaluation. All the model performances in intentionality understanding and perspective-taking together with human baseline performances are presented here (Figure 3). In order to analyze the reasoning abilities of VLMs, we ask the models to explain their answers after they have given the answers.
Human Baseline
We recruited a total of 22 participants, all of whom were college students proficient in English. Participants were instructed to skip any question that was ambiguously phrased or too complex to answer within 90 seconds. A question was marked as failed if the participant did not provide an answer. For each question, at least 80% of participants needed to answer correctly; otherwise, we modified the question, and new annotators completed the revised version. The human baseline result for each question was normalized based on the number of participants who provided an answer.
Results
Overall Performance
Our findings revealed a clear dissociation between model performance in intentionality understanding and perspective-taking. Specifically, all evaluated models demonstrate significantly stronger performance on IntentBench compared to PerspectBench (Figures 3 and 4). This discrepancy becomes even more striking when compared to chance performance: while all models perform above chance performance (approximately 25.00%) on intentionality understanding tasks, not a single model exceeds chance performance (approximately 29.03%) on perspective-taking tasks. Notably, while some of the highest-performing models on IntentBench, such as GPT-4o, achieve near-human accuracy in intentionality comprehension, their performance on PerspectBench lags behind that of the majority of the assessed models (Figure 4). This gap underscores a fundamental limitation in current models, suggesting that perspective-taking might involve distinct cognitive mechanisms that are not yet fully captured by existing architectures.
To quantify this disparity, we conducted a paired samples t-test on the accuracy scores of these models across the two datasets. The analysis revealed a highly significant difference in performance between the two tasks, with a t-statistic of t = 17.651 and a p-value of p = 2.62 × 10-19 (Figure 4). This result provides strong statistical evidence that VLMs exhibit a systematic performance discrepancy, excelling at intentionality understanding while continuing to struggle with perspective-taking. These findings highlight an important challenge for the development of AI systems capable of robust social reasoning and theory of mind.
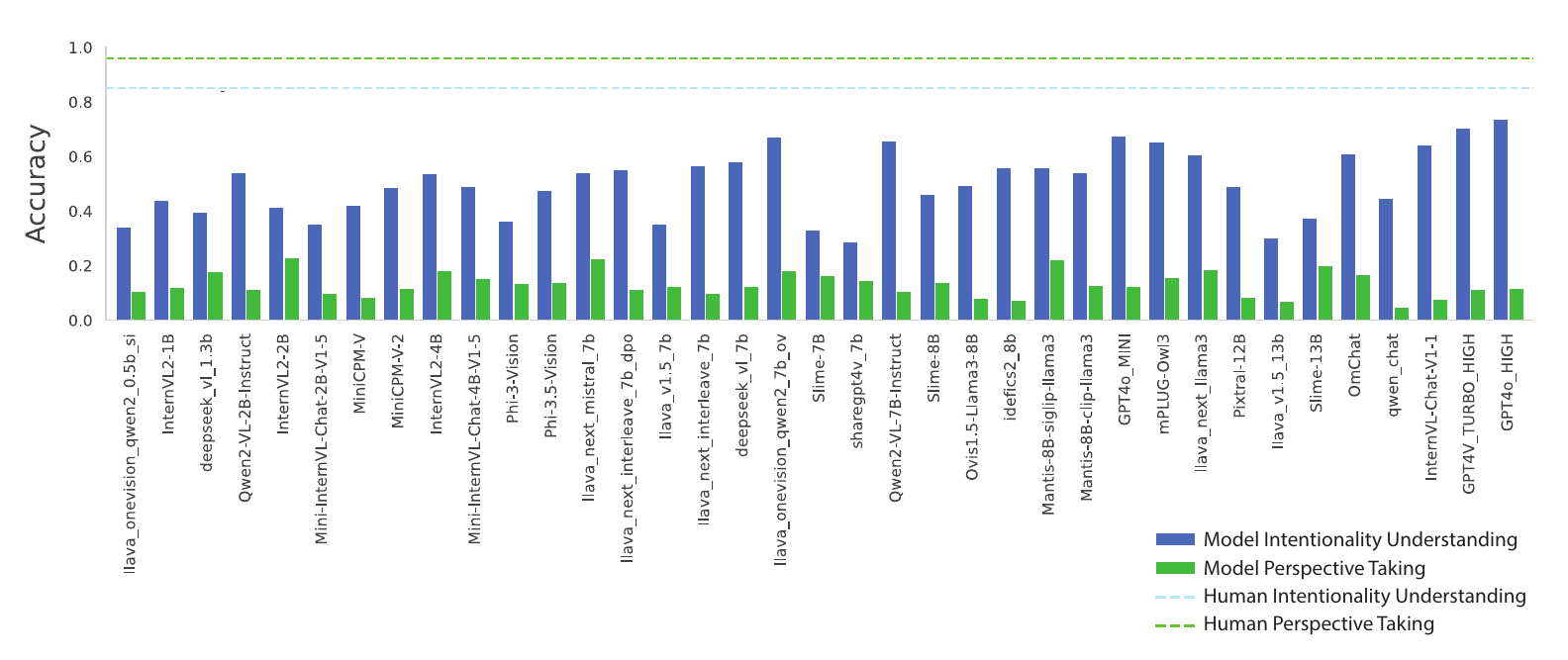 Figure 3: VLMs' Performance on IntentBench and PerspectBench As Compared to Human Baseline
Figure 3: VLMs' Performance on IntentBench and PerspectBench As Compared to Human Baseline
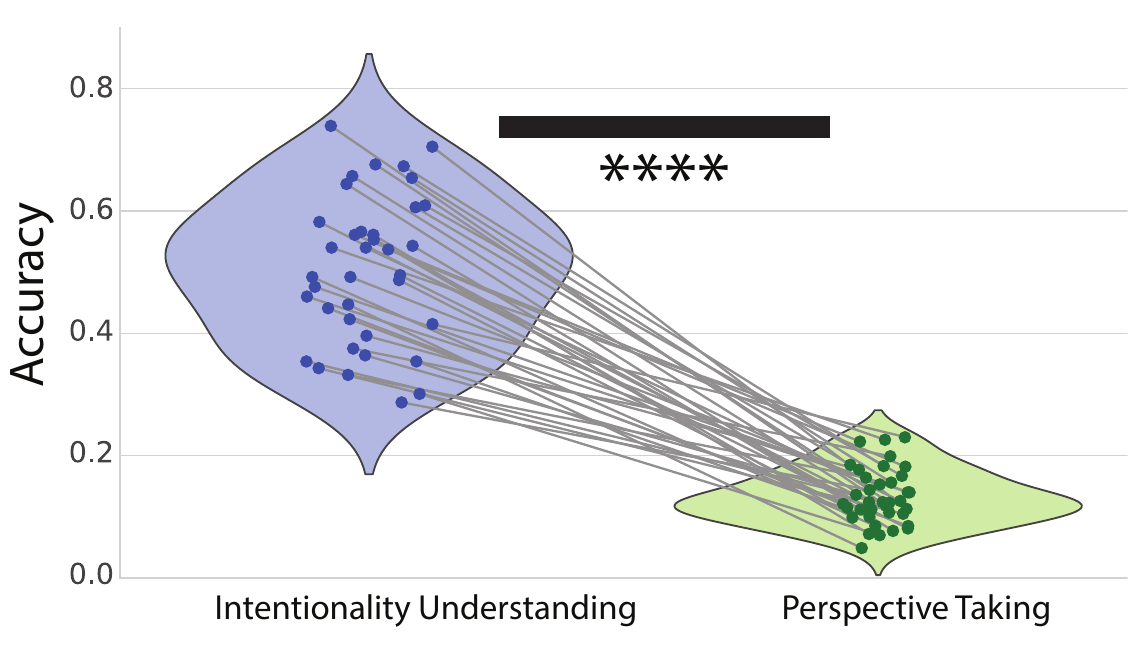 Figure 4: VLMs perform significantly better in intentionality understanding compared to perspective-taking. Paired samples t-test: p = 2.62 × 10-19, t = 17.651.
Figure 4: VLMs perform significantly better in intentionality understanding compared to perspective-taking. Paired samples t-test: p = 2.62 × 10-19, t = 17.651.
Relationship Between Model Performance and Model Size
A common assumption in machine learning is that expanding a model's scale, as measured by the number of parameters, results in systematic enhancements in its reasoning abilities. We examined the degree to which this principle, known as the scaling law hypothesis, holds for the two evaluated cognitive abilities. We observed distinct trends in how intentionality understanding and perspective-taking evolve as VLMs scale in size (Figure 5). While larger models tend to improve in intentionality understanding, their performance in perspective-taking remains largely stagnant—or even declines slightly. This divergence raises important questions about the underlying mechanisms driving these cognitive abilities in AI models and their relationship to model scaling.
 Figure 5: Differential performance changes in intentionality understanding and perspective-taking in VLMs as their model sizes increase. Intentionality understanding: y = 0.0599x + 0.3925, r2 = 0.2797; perspective-taking: y = -0.0057x + 0.1437, r2 = 0.0176).
Figure 5: Differential performance changes in intentionality understanding and perspective-taking in VLMs as their model sizes increase. Intentionality understanding: y = 0.0599x + 0.3925, r2 = 0.2797; perspective-taking: y = -0.0057x + 0.1437, r2 = 0.0176).
To quantitatively assess the impact of model size on performance, we conducted a linear regression analysis of accuracy scores against model size across our 37 VLMs. For intentionality understanding, the coefficient of determination is R2 = 0.2797, with a slope of 0.0599 and an offset of 0.3925. This positive slope indicates that as model size increases, intentionality understanding improves, which aligns with the scaling law hypothesis—the expectation that larger models generally exhibit better performance on cognitive tasks.
The results for perspective-taking reveal a strikingly different trend. The coefficient of determination is much lower at R2 = 0.0176, with a slope of -0.0057 and an offset of 0.1437. The negative slope suggests that, contrary to expectations, larger models do not show significant improvements in perspective-taking ability. In fact, their performance remains largely unchanged or even slightly decreases as they scale. This finding directly contradicts the scaling law hypothesis and suggests that perspective-taking may require fundamentally different cognitive processes that are not naturally enhanced through increased model size alone. This dissociation between intentionality understanding and perspective-taking as models scale highlights a potential limitation in current VLMs. While intentionality understanding appears to benefit from increased parameters and training data, perspective-taking does not seem to follow the same trajectory.
Intercorrelation Between Abilities
We further asked: Are the abilities of intentionality understanding and perspective-taking correlated in VLMs? To investigate this, we computed both Pearson and Spearman correlations between the two measures. The results indicate that there is essentially no relationship between them. The Pearson correlation coefficient is 0.0252 with p = 0.882 and the Spearman correlation coefficient is 0.0115 with p = 0.946. Both results suggest a lack of statistical significance, reinforcing the idea that these two cognitive abilities are largely independent within our assessment of VLMs.
Discussion
In the present work, we assessed VLMs' ability of intentionality understanding and (level-2) perspective-taking. Our results indicated that VLMs appear to be proficient in intentionality understanding while performing significantly worse in perspective-taking.
At the higher levels of the ToM hierarchy, understanding others' intentions requires complex cognitive reasoning about abstract mental states, such as beliefs and values. While this process is cognitively demanding, previous studies suggest that intention understanding may not require explicit perspective-taking but can instead rely on contextual cues, exploiting correlations between environmental features and depicted actions through associative learning. However, intentionality understanding develops much later than level-2 perspective-taking. This developmental gap has made it difficult to directly assess their functional (in)dependency using human participants. By examining these abilities in VLMs, our study likely represents the first direct investigation into their theoretical relationship, highlighting the potential of AI as a theoretical tool for cognitive science.
Furthermore, the observed relationship between model performance on these two abilities and model size carries significant implications for VLM development. The stark contrast in how intentionality understanding and perspective-taking evolve with increasing model size suggests a fundamental difference in the scalability of these abilities within the current architectural paradigm of VLMs. The steady improvement in intentionality understanding, from near-chance performance in smaller models to near-human performance in the largest models, indicates that the attention-based architectures underpinning these models are well-suited for this ability. This suggests that scaling up model parameters is an effective and reliable approach for enhancing intentionality comprehension. In contrast, the persistent failure of all models to exceed chance-level performance on perspective-taking tasks, with larger models performing no better—and even slightly worse—than smaller ones, suggests that this ability may depend on cognitive mechanisms that the current architectures do not support. This finding implies that perspective-taking is not a scalable ability under the current model paradigm and may require fundamental architectural innovations.
As discussed above, level-2 perspective-taking is believed to require model-based reasoning—the ability to construct an internal model of the world to support mental operations, particularly in the visual domain. Our findings reinforce concerns that this hallmark ability of human intelligence might remain absent in VLMs. Moreover, given the lack of scalability observed in level-2 perspective-taking, it is possible that model-based reasoning is fundamentally unacquirable within the current architectural framework of VLMs. This raises important questions about whether alternative approaches—such as explicit world modeling architectures—are necessary to enable model-based reasoning in artificial systems.
One potential concern regarding the experimental paradigms in this study is the discrepancy between the setups used in IntentBench and PerspectBench: the former is based on complex, real-world scenarios, while the latter adapts controlled laboratory designs. This raises the question of whether biases inherent in these differences contribute to the observed performance gap between the two abilities. For instance, images similar to those in IntentBench may be more frequently represented in the training data, whereas models may be less familiar with minimal-context experimental setups like those in PerspectBench. Another concern is whether PerspectBench's design introduces visual confounds that could explain the poor performance. Given recent findings that VLMs struggle with basic visual recognition tasks involving simple shapes and patterns, it is possible that they fail the Three Mountain Task adaptation not due to cognitive limitations but because of visual recognition difficulties.
However, this concern is largely mitigated by the performance patterns observed in PerspectBench. If VLMs primarily struggled with image processing, their scores would cluster around chance level. Instead, all models performed significantly below chance, suggesting a systematic cognitive bias rather than a failure to interpret visual information. This pattern closely mirrors that of children struggling with level-2 perspective-taking tasks, who consistently report what they see from their own perspective rather than considering how others perceive the situation—what Piaget referred to as "egocentrism". Simply put, our results indicate that VLMs are egocentric—but not blind.
Conclusion
Overall, our study represents the first attempt to evaluate VLMs' performance in intentionality understanding and perspective-taking. Our findings suggest that while current VLMs can infer the intentions behind others' actions, they struggle with level-2 perspective-taking. On one hand, this supports the hypothesis that intentionality understanding may not require mental simulation but could instead rely entirely on knowledge-based reasoning. On the other hand, it raises concerns that VLMs lack internal models for reasoning or, at the very least, are unable to leverage them effectively for perspective-taking. This concern is particularly significant given that intentionality understanding improves with model scale, whereas perspective-taking does not. Further research is needed to investigate these findings, as they appear to be crucial for understanding the nature of ToM abilities and their artificial implementations. Exploring the underlying mechanisms behind this dissociation may provide deeper insights into the limitations of current AI models and inform the development of architectures better suited for social reasoning.